線形回帰と最小二乗法
Contents
線形回帰と最小二乗法#
線形回帰#
\(n\)個のデータ \(\left(y_1,x_{11}, \ldots x_{1p}\right),\ldots \left(y_n,x_{n1},\ldots, x_{np}\right)\) を説明変数\(p\)個の線形モデル
で説明することを考える (説明変数が単一の場合を単回帰,複数の場合を重回帰と呼ぶことがある).ここで,
とすると,線形回帰モデルは \(\mathbf{y}=\mathbf{X}\mathbf{\theta}+\mathbf{\varepsilon}\)と書ける.ただし,\(\mathbf{X}\)は計画行列 (design matrix),\(\mathbf{\varepsilon}\)は誤差項である.特に,\(\mathbf{\varepsilon}\)が平均0, 分散\(\sigma^2\)の独立な正規分布に従う場合,\(\mathbf{y}\sim \mathcal{N}(\mathbf{X}\mathbf{\theta}, \sigma^2\mathbf{I})\)と表せる.
最小二乗法によるパラメータの推定#
最小二乗法 (ordinary least squares)により線形回帰のパラメータを推定する.\(y\)の予測値は\(\mathbf{X} \mathbf{\theta}\)なので,誤差 \(\mathbf{\delta} \in \mathbb{R}^n\)は \(\mathbf{\delta} = \mathbf{y}-\mathbf{X} \mathbf{\theta}\)と表せる.ゆえに目的関数\(L(\mathbf{\theta})\)は
となり, \(L(\mathbf{\theta})\)を最小化する\(\mathbf{\theta}\), つまり \(\hat {\mathbf {\theta }}={\underset {\mathbf {\theta}}{\operatorname {arg min} }}\,L({\mathbf{\theta}})\) を求める.
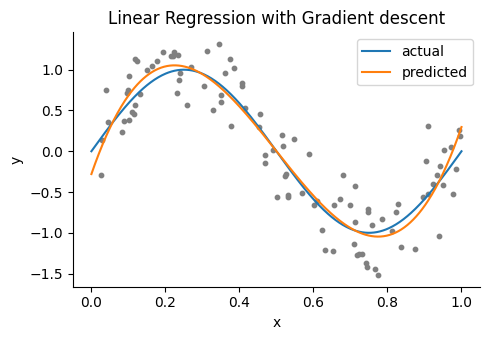
勾配法を用いた推定#
最小二乗法による回帰直線を勾配法で求めてみよう.\(\theta\)の更新式は\(\theta \leftarrow \theta + \alpha\cdot \dfrac{1}{n} \delta \mathbf{X}\)と書ける.ただし,\(\alpha\)は学習率である.
using PyPlot, LinearAlgebra, Random
rc("axes.spines", top=false, right=false)
# Ordinary least squares regression
function OLSRegGradientDescent(X, y, initθ; lr=1e-4, num_iters=10000)
θ = initθ
for i in 1:num_iters
ŷ = X * θ # predictions
δ = y - ŷ # error
θ += lr * X' * δ # Update
end
return θ
end;
# Generate Toy datas
num_train, num_test = 100, 500 # sample size
dims = 4 # dimensions
Random.seed!(0);
x = rand(num_train) #range(0.1, 0.9, length=num_train)
y = sin.(2π*x) + 0.3randn(num_train);
X = hcat([x .^ p for p in 0:dims-1]...); # design matrix
xtest = range(0, 1, length=num_test)
ytest = sin.(2π*xtest)
Xtest =hcat([xtest .^ p for p in 0:dims-1]...);
# Gradient descent
initθ = zeros(dims) # init variables
θgd = OLSRegGradientDescent(X, y, initθ, lr=1e-2, num_iters=1e5)
ŷgd = Xtest * θgd; # predictions
figure(figsize=(5,3.5))
title("Linear Regression with Gradient descent")
scatter(x, y, color="gray", s=10) # samples
plot(xtest, ytest, label="actual") # regression line
plot(xtest, ŷgd, label="predicted") # regression line
xlabel("x"); ylabel("y"); legend()
tight_layout()
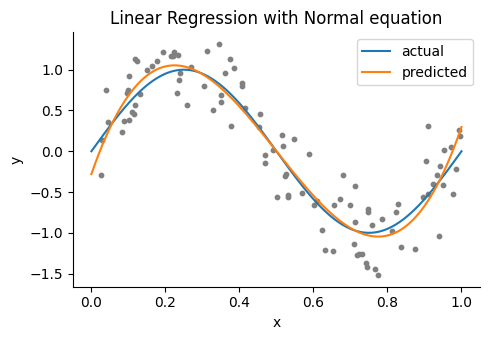
正規方程式を用いた推定#
条件に基づいて目的関数\(L(\mathbf{\theta})\)を微分すると次のような方程式が得られる.
これを正規方程式 (normal equation)と呼ぶ.この正規方程式より、係数の推定値は\(\mathbf{\hat\theta}={(\mathbf{X}^\top\mathbf{X})}^{-1}X^\top\mathbf{y}\)という式で得られる.なお,正規方程式自体は\(\mathbf{y}=\mathbf{X}\mathbf{\theta}\)の左から\(\mathbf{X}^\top\)をかける,と覚えると良い.
θne = (X' * X) \ X' * y
ŷne = Xtest * θne; # predictions
figure(figsize=(5,3.5))
title("Linear Regression with Normal equation")
scatter(x, y, color="gray", s=10) # samples
plot(xtest, ytest, label="actual") # regression line
plot(xtest, ŷne, label="predicted") # regression line
xlabel("x"); ylabel("y"); legend()
tight_layout()