スパース符号化
Contents
スパース符号化#
Sparse codingと生成モデル#
Sparse codingモデル [Olshausen and Field, 1996] [Olshausen and Field, 1997]はV1のニューロンの応答特性を説明する線形生成モデル (linear generative model)である.まず,画像パッチ \(\mathbf{x}\) が基底関数(basis function) \(\mathbf{\Phi} = [\phi_j]\) のノイズを含む線形和で表されるとする (係数は \(\mathbf{r}=[r_j]\) とする).
ただし,\(\boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \sigma^2 \mathbf{I})\) である.このモデルを神経ネットワークのモデルと考えると, \(\mathbf{\Phi}\) は重み行列,係数 \(\mathbf{r}\) は入力よりも高次の神経細胞の活動度を表していると解釈できる.ただし,\(r_j\) は負の値も取るので単純に発火率と捉えられないのはこのモデルの欠点である.
Sparse codingでは神経活動 \(\mathbf{r}\) が潜在変数の推定量を表現しているという仮定の下,少数の基底で画像 (や目的変数)を表すことを目的とする.要は上式において,ほとんどが0で,一部だけ0以外の値を取るという疎 (=sparse)な係数\(\mathbf{r}\)を求めたい.
確率的モデルの記述#
入力される画像パッチ \(\mathbf{x}_i\ (i=1, \ldots, N)\) の真の分布を \(p_{data}(\mathbf{x})\) とする.また,\(\mathbf{x}\) の生成モデルを \(p(\mathbf{x}|\mathbf{\Phi})\) とする.さらに潜在変数 \(\mathbf{r}\) の事前分布 (prior)を \(p(\mathbf{r})\), 画像パッチ \(\mathbf{x}\) の尤度 (likelihood)を \(p(\mathbf{x}|\mathbf{r}, \mathbf{\Phi})\) とする.このとき,
が成り立つ.\(p(\mathbf{x}|\mathbf{r}, \mathbf{\Phi})\)は,(1)式においてノイズ項を\(\boldsymbol{\epsilon} \sim\mathcal{N}(\mathbf{0}, \sigma^2 \mathbf{I})\)としたことから,
と表せる.ただし,\(Z_{\sigma}\)は規格化定数である.
事前分布の設定#
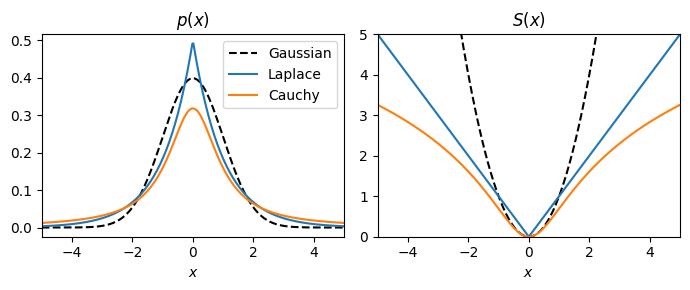
事前分布\(p(\mathbf{r})\)としては,0においてピークがあり,裾の重い(heavy tail)を持つsparse distributionあるいは super-Gaussian distribution (Laplace 分布やCauchy分布などGaussian分布よりもkurtoticな分布)を用いるのが良い.このような分布では,\(\mathbf{r}\)の各要素\(r_i\)はほとんど0に等しく,ある入力に対しては大きな値を取る.\(p(\mathbf{r})\)は一般化して式(4), (5)のように表記する.
ただし,\(\beta\)は逆温度(inverse temperature), \(Z_{\beta}\)は規格化定数 (分配関数) である1.\(S(x)\)と分布の関係をまとめた表が以下となる (cf. Harpur, 1997).
\(S(r)\) |
\(\dfrac{dS(r)}{dr}\) |
\(p(r)\) |
分布名 |
尖度(kurtosis) |
|---|---|---|---|---|
\(r^2\) |
\(2r\) |
\(\dfrac{1}{\alpha \sqrt{2\pi}}\exp\left(-\dfrac{r^2}{2\alpha^2}\right)\) |
Gaussian 分布 |
0 |
\(\vert r\vert\) |
\(\text{sign}(r)\) |
\(\dfrac{1}{2\alpha}\exp\left(-\dfrac{\vert r\vert}{\alpha}\right)\) |
Laplace 分布 |
3.0 |
\(\ln (\alpha^2+r^2)\) |
\(\dfrac{2r}{\alpha^2+r^2}\) |
\(\dfrac{\alpha}{\pi}\dfrac{1}{\alpha^2+r^2}=\dfrac{\alpha}{\pi}\exp[-\ln (\alpha^2+r^2)]\) |
Cauchy 分布 |
- |
分布\(p(r)\)や\(S(r)\)を描画すると次のようになる.
using PyPlot
x = range(-5, 5, length=300)
figure(figsize=(7,3))
subplot(1,2,1)
title(L"$p(x)$")
plot(x, 1/sqrt(2pi)*exp.(-(x.^2)/2), color="black", linestyle="--",label="Gaussian")
plot(x, 1/2*exp.(-abs.(x)), label="Laplace")
plot(x, 1 ./ (pi*(1 .+ x.^2)), label="Cauchy")
xlim(-5, 5);
xlabel(L"$x$")
legend()
subplot(1,2,2)
title(L"S(x)")
plot(x, x.^2, color="black", linestyle="--",label="Gaussian")
plot(x, abs.(x), label="Laplace")
plot(x, log.(1 .+ x.^2), label="Cauchy")
xlim(-5, 5); ylim(0, 5)
xlabel(L"$x$")
tight_layout()
目的関数の設定と最適化#
最適な生成モデルを得るために,入力される画像パッチの真の分布 \(p_{data}(\mathbf{x})\)と\(\mathbf{x}\)の生成モデル \(p(\mathbf{x}|\mathbf{\Phi})\)を近づける.このために,2つの分布のKullback-Leibler ダイバージェンス \(D_{\text{KL}}\left(p_{data}(\mathbf{x}) \Vert\ p(\mathbf{x}|\mathbf{\Phi})\right)\)を最小化したい.しかし,真の分布は得られないので,経験分布
を近似として用いる (\(\delta(\cdot)\) はDiracのデルタ関数である).ゆえに\(D_{\text{KL}}\left(\hat{p}_{data}(\mathbf{x}) \Vert\ p(\mathbf{x}|\mathbf{\Phi})\right)\)を最小化する.
が成り立つ.(7)式の1番目の項は一定なので,\(D_{\text{KL}}\left(\hat{p}_{data}(\mathbf{x}) \Vert\ p(\mathbf{x}|\mathbf{\Phi})\right)\) を最小化するには\(\mathbb{E}_{\hat{p}_{data}} \left[\ln p(\mathbf{x}|\mathbf{\Phi})\right]\)を最大化すればよい.ここで,
が成り立つ.また,(2)式より
が成り立つので,近似として \(\displaystyle \int p(\mathbf{x}|\mathbf{r}, \mathbf{\Phi})p(\mathbf{r})d\mathbf{r}\) を \(p(\mathbf{x}|\mathbf{r}, \mathbf{\Phi})p(\mathbf{r}) \left(=p(\mathbf{x}, \mathbf{r}| \mathbf{\Phi})\right)\) で評価する.これらの近似の下,最適な\(\mathbf{\Phi}=\mathbf{\Phi}^*\)は次のようにして求められる.
ただし,\(\mathbf{x}_i\)に対する神経活動を \(\mathbf{r}_i\)とした.また,\(E(\mathbf{x}, \mathbf{r}|\mathbf{\Phi})\)はコスト関数であり,次式のように表される.
ただし,\(\lambda=2\sigma^2\beta\)は正則化係数2であり,1行目から2行目へは式(3), (4), (5)を用いた.ここで,第1項が復元損失,第2項が罰則項 (正則化項)となっている.
式(9)で表される最適化手順を最適な\(\mathbf{r}\)と\(\mathbf{\Phi}\)を求める過程に分割しよう.まず, \(\mathbf{\Phi}\)を固定した下で\(E(\mathbf{x}_n, \mathbf{r}_i|\mathbf{\Phi})\)を最小化する\(\mathbf{r}_i=\hat{\mathbf{r}}_i\)を求める (11.1.3).
これは \(\mathbf{r}\) について MAP推定 (maximum a posteriori estimation)を行うことに等しい.次に\(\hat{\mathbf{r}}\)を用いて
とすることにより,\(\mathbf{\Phi}\)を最適化する (11.1.4).こちらは \(\mathbf{\Phi}\) について 最尤推定 (maximum likelihood estimation)を行うことに等しい.
Locally competitive algorithm (LCA)#
\(\mathbf{r}\)の勾配法による更新則は,\(E\)の微分により次のように得られる.
ただし,\(\eta_{\mathbf{r}}\)は学習率である.この式により\(\mathbf{r}\)が収束するまで最適化するが,単なる勾配法ではなく,[Olshausen and Field, 1996]では共役勾配法 (conjugate gradient method)を用いている.しかし,共役勾配法は実装が煩雑で非効率であるため,より効率的かつ生理学的な妥当性の高い学習法として,LCA (locally competitive algorithm)が提案されている [Rozell et al., 2008].LCAは側抑制 (local competition, lateral inhibition)と閾値関数 (thresholding function)を用いる更新則である.LCAによる更新を行うRNNは通常のRNNとは異なり,コスト関数(またはエネルギー関数)を最小化する動的システムである.このような機構はHopfield networkで用いられているために,OlshausenはHopfield trickと呼んでいる.
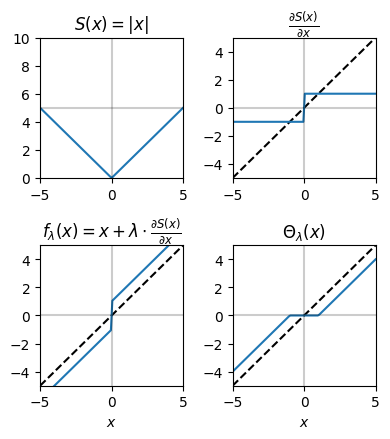
軟判定閾値関数を用いる場合 (ISTA)#
\(S(x)=|x|\)とした場合の閾値関数を用いる手法としてISTA(Iterative Shrinkage Thresholding Algorithm)がある.ISTAはL1-norm正則化項に対する近接勾配法で,要はLasso回帰に用いる勾配法である.
解くべき問題は次式で表される.
詳細は後述するが,次のように更新することで解が得られる.
\(\mathbf{r}(0)\)を要素が全て0のベクトルで初期化:\(\mathbf{r}(0)=\mathbf{0}\)
\(\mathbf{r}_*(t+1)=\mathbf{r}(t)+\eta_\mathbf{r}\cdot \mathbf{\Phi}^\top(\mathbf{x}-\mathbf{\Phi}\mathbf{r}(t))\)
\(\mathbf{r}(t+1) = \Theta_\lambda(\mathbf{r}_*(t+1))\)
\(\mathbf{r}\)が収束するまで2と3を繰り返す
ここで\(\Theta_\lambda(\cdot)\)は軟判定閾値関数 (Soft thresholding function)と呼ばれ,次式で表される.
\(\Theta_\lambda(\cdot)\)を関数として定義すると次のようになる.また,ReLU (ランプ関数)はmax(x, 0)で実装できる.この点から考えればReLUを軟判定非負閾値関数 (soft nonnegative thresholding function)と捉えることもできる [Papyan et al., 2018].
# thresholding function of S(x)=|x|
soft_thres(x, λ) = max(x - λ, 0) - max(-x - λ, 0)
soft_nonneg_thres(x, λ) = max(x - λ, 0) # relu(x-λ)
soft_nonneg_thres (generic function with 1 method)
次に\(\Theta_\lambda(\cdot)\)を描画すると次のようになる.
xmin, xmax = -5, 5
x = range(xmin, xmax, length=100)
y = soft_thres.(x, 1)
figure(figsize=(4,4.5))
subplot(2,2,1)
title(L"$S(x)=|x|$")
plot(x, abs.(x))
xlim(xmin, xmax); ylim(0, 10)
hlines(y=xmax, xmin=xmin, xmax=xmax, color="k", alpha=0.2)
vlines(x=0, ymin=0, ymax=xmax*2, color="k", alpha=0.2)
subplot(2,2,2)
title(L"$\frac{\partial S(x)}{\partial x}$")
plot(x, x, "k--")
plot(x, sign.(x))
xlim(xmin, xmax); ylim(xmin, xmax)
hlines(y=0, xmin=xmin, xmax=xmax, color="k", alpha=0.2)
vlines(x=0, ymin=xmin, ymax=xmax, color="k", alpha=0.2)
subplot(2,2,3)
title(L"$f_\lambda(x)=x+\lambda\cdot\frac{\partial S(x)}{\partial x}$")
plot(x, x, "k--")
plot(x, x + 1*sign.(x))
xlabel(L"$x$")
xlim(-5, 5); ylim(-5, 5)
hlines(y=0, xmin=xmin, xmax=xmax, color="k", alpha=0.2)
vlines(x=0, ymin=xmin, ymax=xmax, color="k", alpha=0.2)
subplot(2,2,4)
title(L"$\Theta_\lambda(x)$")
plot(x, x, "k--")
plot(x, y)
xlabel(L"$x$")
xlim(-5, 5); ylim(-5, 5)
hlines(y=0, xmin=xmin, xmax=xmax, color="k", alpha=0.2)
vlines(x=0, ymin=xmin, ymax=xmax, color="k", alpha=0.2)
tight_layout()
なお,軟判定閾値関数は次の目的関数\(C\)を最小化する\(x\)を求めることで導出できる.
ただし,\(x, y, \lambda\)はスカラー値とする.\(|x|\)が微分できないが,これは場合分けを考えることで解決する.\(x\geq 0\)を考えると,(6)式は
となる.(7)式の最小値を与える\(x\)は場合分けをして考えると,\(y-\lambda\geq0\)のとき二次関数の頂点を考えて\(x=y-\lambda\)となる. 一方で\(y-\lambda<0\)のときは\(x\geq0\)において単調増加な関数となるので,最小となるのは\(x=0\)のときである.同様の議論を\(x\leq0\)に対しても行うことで (5)式が得られる.
なお,閾値関数としては軟判定閾値関数だけではなく,硬判定閾値関数や\(y=x - \text{tanh}(x)\) (Tanh-shrink)など様々な関数を用いることができる.
重み行列の更新則#
\(\mathbf{r}\)が収束したら勾配法により\(\mathbf{\Phi}\)を更新する.
Sparse coding networkの実装#
ネットワークは入力層を含め2層の単純な構造である.今回は,入力はランダムに切り出した16×16 (=256)の画像パッチとし,これを入力層の256個のニューロンが受け取るとする.入力層のニューロンは次層の100個のニューロンに投射するとする.100個のニューロンが入力をSparseに符号化するようにその活動および重み行列を最適化する.
画像データの読み込み#
データはhttp://www.rctn.org/bruno/sparsenet/からダウンロードできる 3.IMAGES_RAW.matは10枚の自然画像で,IMAGES.matはそれを白色化したものである.matファイルの読み込みにはMAT.jlを用いる.
using MAT
#using PyPlot
# datasets from http://www.rctn.org/bruno/sparsenet/
mat_images_raw = matopen("../_static/datasets/IMAGES_RAW.mat")
imgs_raw = read(mat_images_raw, "IMAGESr")
mat_images = matopen("../_static/datasets/IMAGES.mat")
imgs = read(mat_images, "IMAGES")
close(mat_images_raw)
close(mat_images)
画像データを描画する.
figure(figsize=(8, 3))
subplots_adjust(hspace=0.1, wspace=0.1)
for i=1:10
subplot(2, 5, i)
imshow(imgs_raw[:,:,i], cmap="gray")
axis("off")
end
suptitle("Natural Images", fontsize=12)
subplots_adjust(top=0.9)

モデルの定義#
必要なパッケージを読み込む.
using Base: @kwdef
using Parameters: @unpack # or using UnPack
using LinearAlgebra, Random, Statistics, ProgressMeter
Random.seed!(0)
rc("axes.spines", top=false, right=false)
モデルを定義する.
@kwdef struct OFParameter{FT}
lr_r::FT = 1e-2 # learning rate of r
lr_Phi::FT = 1e-2 # learning rate of Phi
λ::FT = 5e-3 # regularization parameter
end
@kwdef mutable struct OlshausenField1996Model{FT}
param::OFParameter = OFParameter{FT}()
num_inputs::Int32
num_units::Int32
batch_size::Int32
r::Array{FT} = zeros(batch_size, num_units) # activity of neurons
Phi::Array{FT} = randn(num_inputs, num_units) .* sqrt(1/num_units)
end
パラメータを更新する関数を定義する.今回はより生理学的に妥当にするため,軟判定非負閾値関数を用いる.
function updateOF!(variable::OlshausenField1996Model, param::OFParameter, inputs::Array, training::Bool)
@unpack num_inputs, num_units, batch_size, r, Phi = variable
@unpack lr_r, lr_Phi, λ = param
# Updates
error = inputs .- r * Phi'
r_ = r +lr_r .* error * Phi
#r[:, :] = soft_thres.(r_, λ)
r[:, :] = soft_nonneg_thres.(r_, λ)
if training
error = inputs - r * Phi'
dPhi = error' * r
Phi[:, :] += lr_Phi * dPhi
end
return error
end
updateOF! (generic function with 1 method)
行ごとに正規化する関数を定義する.
function normalize_rows(A::Array)
return A ./ sqrt.(sum(A.^2, dims=1) .+ 1e-8)
end
normalize_rows (generic function with 1 method)
損失関数を定義する.
function calculate_total_error(error, r, λ)
recon_error = mean(error.^2)
sparsity_r = λ*mean(abs.(r))
return recon_error + sparsity_r
end
calculate_total_error (generic function with 1 method)
シミュレーションを実行する関数を定義する.外側のfor loopでは画像パッチの作成とrの初期化を行う.内側のfor loopではrが収束するまで更新を行い,収束したときに重み行列Phiを更新する.
function run_simulation(imgs, num_iter, nt_max, batch_size, sz, num_units, eps)
H, W, num_images = size(imgs)
num_inputs = sz^2
model = OlshausenField1996Model{Float32}(num_inputs=num_inputs, num_units=num_units, batch_size=batch_size)
errorarr = zeros(num_iter) # Vector to save errors
# Run simulation
@showprogress "Computing..." for iter in 1:num_iter
# Get the coordinates of the upper left corner of clopping image randomly.
beginx = rand(1:W-sz, batch_size)
beginy = rand(1:H-sz, batch_size)
inputs = zeros(batch_size, num_inputs) # Input image patches
# Get images randomly
for i in 1:batch_size
idx = rand(1:num_images)
img = imgs[:, :, idx]
clop = img[beginy[i]:beginy[i]+sz-1, beginx[i]:beginx[i]+sz-1][:]
inputs[i, :] = clop .- mean(clop)
end
model.r = zeros(batch_size, num_units) # Reset r states
model.Phi = normalize_rows(model.Phi) # Normalize weights
# Input image patches until latent variables are converged
r_tm1 = zeros(batch_size, num_units) # set previous r (t minus 1)
for t in 1:nt_max
# Update r without update weights
error = updateOF!(model, model.param, inputs, false)
dr = model.r - r_tm1
# Compute norm of r
dr_norm = sqrt(sum(dr.^2)) / sqrt(sum(r_tm1.^2) + 1e-8)
r_tm1 .= model.r # update r_tm1
# Check convergence of r, then update weights
if dr_norm < eps
error = updateOF!(model, model.param, inputs, true)
errorarr[iter] = calculate_total_error(error, model.r, model.param.λ) # Append errors
break
end
# If failure to convergence, break and print error
if t >= nt_max-1
print("Error at patch:", iter_, dr_norm)
errorarr[iter] = calculate_total_error(error, model.r, model.param.λ) # Append errors
break
end
end
# Print moving average error
if iter % 100 == 0
moving_average_error = mean(errorarr[iter-99:iter])
println("iter: ", iter, "/", num_iter, ", Moving average error:", moving_average_error)
end
end
return model, errorarr
end
run_simulation (generic function with 1 method)
r_tm1 .= model.rの部分は,要素ごとのコピーを実行している.r_tm1 = copy(model.r)でもよいが,新たなメモリ割り当てが生じるので避けている.@. r_tm1 = model.rとしてもよい.
シミュレーションの実行#
# Simulation constants
num_iter = 500 # number of iterations
nt_max = 1000 # Maximum number of simulation time
batch_size = 250 # Batch size
sz = 16 # image patch size
num_units = 100 # number of neurons (units)
eps = 1e-2 # small value which determines convergence
model, errorarr = run_simulation(imgs, num_iter, nt_max, batch_size, sz, num_units, eps);
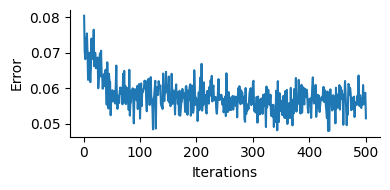
訓練中の損失の描画#
訓練中の損失の変化を描画してみよう.損失が低下し,学習が進行したことが分かる.
# Plot error
figure(figsize=(4, 2))
ylabel("Error")
xlabel("Iterations")
plot(1:num_iter, errorarr)
tight_layout()
重み行列 (受容野)の描画#
学習後の重み行列 Phi (\(\mathbf{\Phi}\))を可視化してみよう.
# Plot Receptive fields
figure(figsize=(4.2, 4))
subplots_adjust(hspace=0.1, wspace=0.1)
for i in 1:num_units
subplot(10, 10, i)
imshow(reshape(model.Phi[:, i], (sz, sz)), cmap="gray")
axis("off")
end
suptitle("Receptive fields", fontsize=14)
subplots_adjust(top=0.925)

白色がON領域(興奮),黒色がOFF領域(抑制)を表す.Gaborフィルタ様の局所受容野が得られており,これは一次視覚野(V1)における単純型細胞(simple cells)の受容野に類似している.
画像の再構成#
学習したモデルを用いて入力画像が再構成されるか確認しよう.
H, W, num_images = size(imgs)
num_inputs = sz^2
# Get the coordinates of the upper left corner of clopping image randomly.
beginx = rand(1:W-sz, batch_size)
beginy = rand(1:H-sz, batch_size)
inputs = zeros(batch_size, num_inputs) # Input image patches
# Get images randomly
for i in 1:batch_size
idx = rand(1:num_images)
img = imgs[:, :, idx]
clop = img[beginy[i]:beginy[i]+sz-1, beginx[i]:beginx[i]+sz-1][:]
inputs[i, :] = clop .- mean(clop)
end
model.r = zeros(batch_size, num_units) # Reset r states
# Input image patches until latent variables are converged
r_tm1 = zeros(batch_size, num_units) # set previous r (t minus 1)
for t in 1:nt_max
# Update r without update weights
error = updateOF!(model, model.param, inputs, false)
dr = model.r - r_tm1
# Compute norm of r
dr_norm = sqrt(sum(dr.^2)) / sqrt(sum(r_tm1.^2) + 1e-8)
r_tm1 .= model.r # update r_tm1
# Check convergence of r, then update weights
if dr_norm < eps
break
end
end;
神経活動 \(\mathbf{r}\)がスパースになっているか確認しよう.
figure(figsize=(3, 2))
hist(model.r[:], bins=50)
xlim(0, 0.5)
tight_layout()
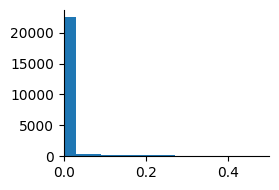
要素がほとんど0のスパースなベクトルになっていることがわかる.次に画像を再構成する.
reconst = model.r * model.Phi'
println(size(reconst))
(250, 256)
再構成した結果を描画する.
figure(figsize=(7.5, 3))
subplots_adjust(hspace=0.1, wspace=0.1)
num_show = 5
for i in 1:num_show
subplot(2, num_show, i)
imshow(reshape(inputs[i, :], (sz, sz)), cmap="gray")
xticks([]); yticks([]);
if i == 1
ylabel("Input\n images")
end
subplot(2, num_show, num_show+i)
imshow(reshape(reconst[i, :], (sz, sz)), cmap="gray")
xticks([]); yticks([]);
if i == 1
ylabel("Reconstructed\n images")
end
end

上段が入力画像,下段が再構成された画像である.差異はあるものの,概ね再構成されていることがわかる.
参考文献#
- OF96(1,2)
B A Olshausen and D J Field. Emergence of simple-cell receptive field properties by learning a sparse code for natural images. Nature, 381(6583):607–609, June 1996.
- OF97
B A Olshausen and D J Field. Sparse coding with an overcomplete basis set: a strategy employed by v1? Vision Res., 37(23):3311–3325, December 1997.
- PRSE18
Vardan Papyan, Yaniv Romano, Jeremias Sulam, and Michael Elad. Theoretical foundations of deep learning via sparse representations: a multilayer sparse model and its connection to convolutional neural networks. IEEE Signal Process. Mag., 35(4):72–89, July 2018.
- RJBO08
Christopher J Rozell, Don H Johnson, Richard G Baraniuk, and Bruno A Olshausen. Sparse coding via thresholding and local competition in neural circuits. Neural Comput., 20(10):2526–2563, October 2008.
論文以外の参考資料
Bruno Olshausen: “Sparse coding in brains and machines”(Stanford talks), Slide
https://redwood.berkeley.edu/wp-content/uploads/2018/08/sparse-coding-ICA.pdf
https://redwood.berkeley.edu/wp-content/uploads/2018/08/sparse-coding-LCA.pdf
https://redwood.berkeley.edu/wp-content/uploads/2018/08/Dylan-lca_overcompleteness_09-27-2018.pdf
- 1
これらの用語は統計力学における正準分布 (ボルツマン分布)から来ている.
- 2
この式から逆温度\(\beta\)が正則化の度合いを調整するパラメータであることがわかる.
- 3
これはアメリカ北西部で撮影された自然画像であり,van Hateren’s Natural Image Datasetから取得されたものである.